
In today’s AI-driven world, the demand for fresh, structured web data has never been higher. This data is the lifeblood of everything from Retrieval-Augmented Generation (RAG) pipelines and competitive intelligence dashboards to autonomous AI agents. However, reliably extracting this information is a persistent challenge; websites are complex, constantly changing, and often protected by anti-scraping measures. This article explores two leading platforms designed to solve this problem: Firecrawl, an API-first crawler optimized for AI applications, and Apify, a comprehensive web scraping and automation ecosystem. We’ll delve into their core architectures, pricing models, and ideal use cases to help you determine which tool—or combination of tools—is the right fit for your projects in 2025.
This guide will provide a detailed comparison, breaking down the technical capabilities and strategic advantages of each platform.
- Firecrawl’s Core Strengths and Technical Architecture
- Apify’s Ecosystem and Flexibility
- Pricing Models and Performance Comparison
- Integration Solutions and Recommended Use Cases
Firecrawl’s Core Strengths and Technical Architecture
Firecrawl emerged from the AI revolution with a clear focus: to provide developers with a simple, fast, and reliable way to feed data into large language models (LLMs). It abstracts away the complexities of traditional web scraping behind a clean, unified API.
Firecrawl offers a unified, AI-driven API designed for speed and simplicity, converting web pages into LLM-ready data without manual selectors.
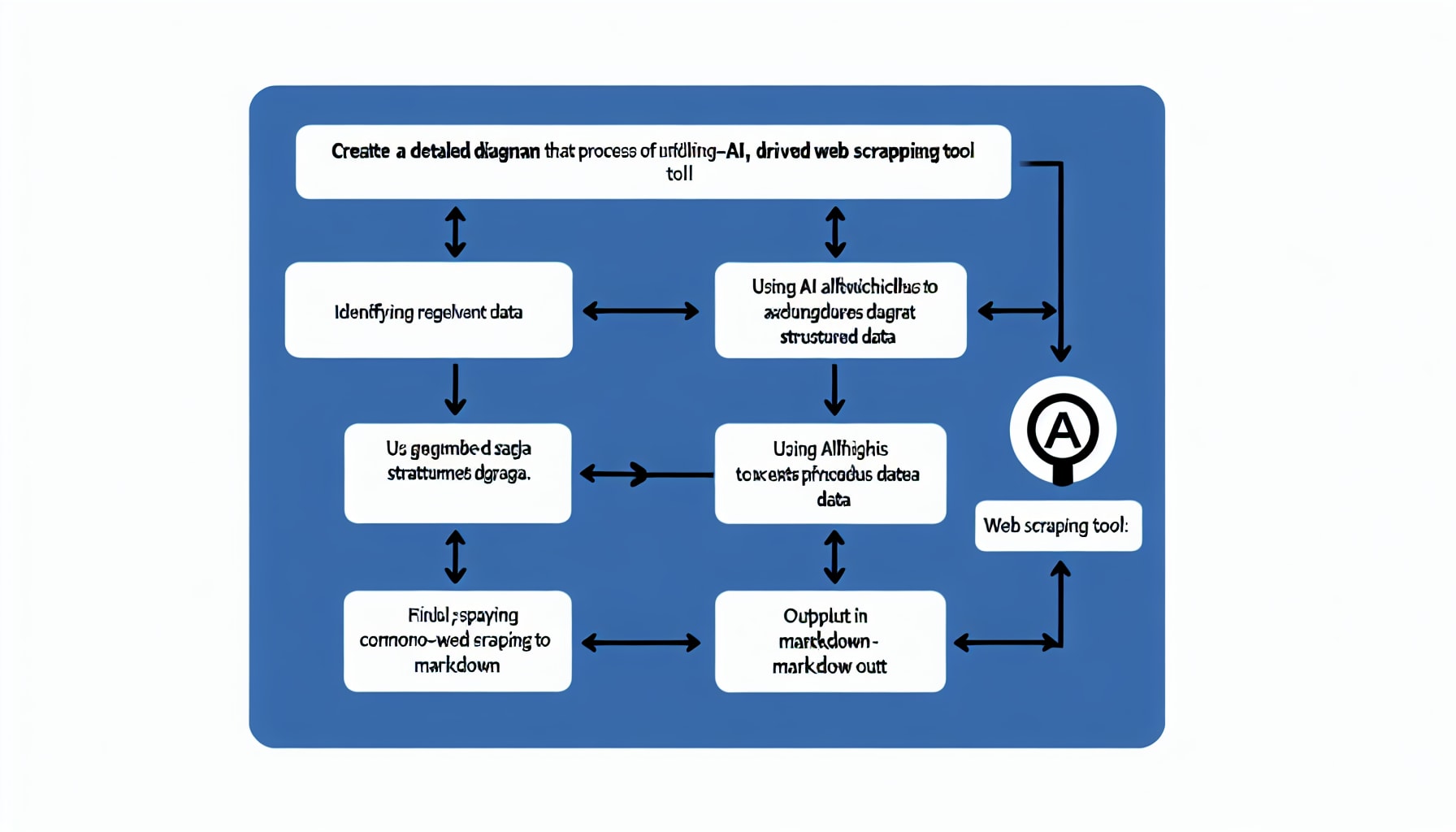
Unified AI-driven Scraping Architecture
Firecrawl’s architecture is built around a single, consistent API that handles scraping, crawling, and AI-powered extraction. When a request is made, the service intelligently determines whether a simple HTTP fetch is sufficient or if it needs to spin up a headless browser to render JavaScript-heavy content. This process is entirely automated, meaning developers don’t need to configure different settings for static and dynamic sites. The platform’s goal is to turn any URL into clean, usable data with a single API call, significantly reducing development overhead.
Natural Language Extraction and Selector-less Design
One of Firecrawl’s most compelling features is its “zero-selector” extraction capability. Instead of writing brittle CSS or XPath selectors that break whenever a website’s layout changes, developers can describe the data they need in plain English. For example, a prompt like “Extract the product name, price, and availability” will return a structured JSON object with the requested information. This natural language approach not only simplifies the initial setup but also makes the scraper far more resilient to website updates. The platform also excels at converting raw HTML into clean, LLM-friendly Markdown, which can reduce token counts for downstream AI applications by up to 67%.
Firecrawl offers a single, consistent API that handles scraping, crawling, and AI‑driven site navigation, so developers never have to juggle multiple endpoints or bespoke parameters. When you request a page, the service decides on‑the‑fly whether it needs a headless browser, waits for all dynamic elements to render, and then applies extraction models that automatically ignore ads, menus, and other noise.
Caching and High-Concurrency Handling
Performance is a cornerstone of the Firecrawl platform. It maintains a pool of pre-warmed browsers and a global cache, allowing it to serve recently scraped pages in milliseconds. For larger jobs, Firecrawl supports batching hundreds of URLs in a single API call, processing them in parallel to maximize throughput. This architecture is particularly beneficial for real-time applications and AI agents that require low-latency access to web data. Even on its mid-tier plans, the platform can process thousands of pages per minute, making it a powerful tool for both small-scale projects and high-volume operations. This focus on speed is a key reason why many teams building AI-powered applications are turning to Firecrawl.
Apify’s Ecosystem and Flexibility
Founded in 2015, Apify has spent nearly a decade building a comprehensive web scraping ecosystem. It approaches the problem not as a single-tool exercise but as a platform challenge, offering a vast library of pre-built solutions, powerful developer tools, and enterprise-grade infrastructure.
Apify provides a flexible, end-to-end scraping ecosystem built around a marketplace of pre-built tools and robust developer SDKs.
Rich Marketplace of Pre-built Scrapers
At the heart of Apify is the Actor system—containerized cloud programs that can perform any web scraping or automation task. This standardization has fueled the Apify Store, a marketplace with over 6,000 pre-built Actors for virtually every major website and use case imaginable. Whether you need product data from Amazon, social media statistics from Instagram, or information from a niche government registry, there is likely an Actor that already does the job. These Actors are maintained by a community of developers, ensuring they stay functional even as target sites change. This allows teams to start collecting data in hours, not weeks.
Multi-language SDKs and Developer Tools
When an off-the-shelf Actor isn’t a perfect fit, developers can build their own using the Apify SDK. This SDK, also available as the popular open-source library Crawlee, supports both JavaScript/TypeScript and Python. It provides high-level abstractions for complex tasks like request queuing, proxy rotation, and error handling, while still allowing developers to drop down to low-level tools like Playwright or Puppeteer for fine-grained control. This flexibility makes it easy to integrate custom scraping logic into existing codebases and development workflows.
Apify approaches web scraping as an ecosystem problem rather than a single‑tool exercise. Its foundation is the Actor system — self‑contained programs that run in Apify’s cloud with uniform input/output, shared storage, and common scheduling and monitoring. Because every Actor behaves the same way, you can link them into multistep workflows just by passing data from one to the next.
Elastic Scaling and Enterprise-Grade Compliance
Apify is built for scale. The platform automatically scales compute resources based on demand, allowing users to run thousands of Actors in parallel for bursty, large-scale jobs. It manages a vast pool of datacenter and residential proxies, applying sophisticated anti-detection techniques to ensure reliable data collection. For enterprise clients, Apify offers critical features like SOC 2 Type II and GDPR compliance, detailed monitoring, alerting, and real-time webhooks for seamless integration with downstream systems. This combination of scalability and security makes Apify a trusted choice for large organizations with demanding data needs.
Pricing Models and Performance Comparison
The financial and performance implications of choosing a scraping platform are significant. Firecrawl and Apify have fundamentally different pricing structures, each with distinct advantages depending on the use case.
Firecrawl’s simple credit-based pricing offers predictability, while Apify’s hybrid model provides flexibility that can be more cost-effective for certain large-scale or complex jobs.
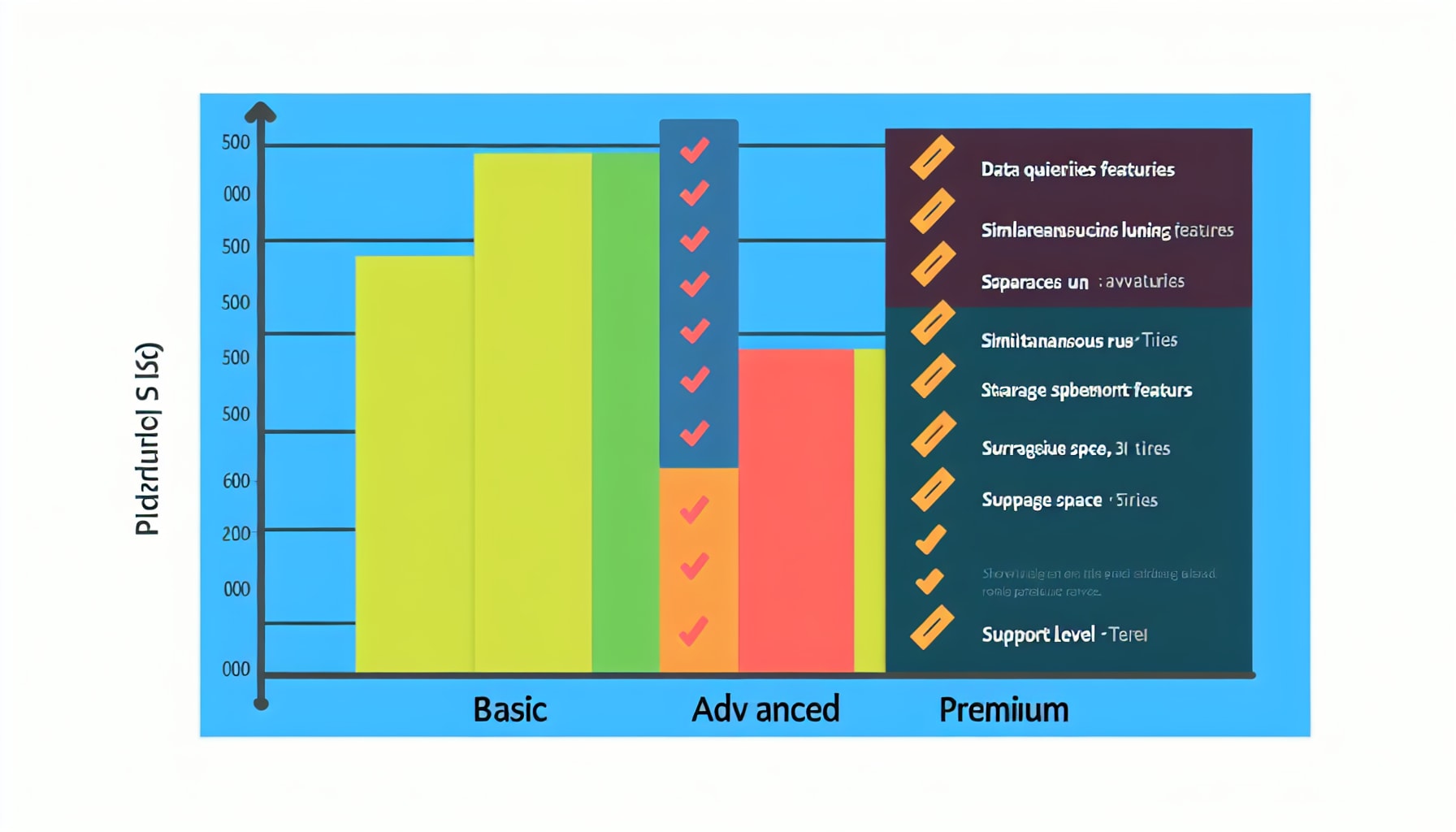
Firecrawl’s Simple and Transparent Credit Billing
Firecrawl uses a straightforward, credit-based model where one standard page scrape typically consumes one credit. This makes it incredibly easy to predict costs. For instance, the Hobby plan at $16 per month includes 3,000 credits, while the Standard plan offers 100,000 credits for $83 per month. This transparency is a major advantage for teams that need to budget their expenses precisely. The pricing model covers all associated costs, including proxies and compute resources, so there are no hidden fees.
Apify’s Complex Subscription and Resource-Consumption Hybrid Billing
Apify employs a more complex hybrid model that combines a monthly subscription with consumption-based billing. Each plan includes a certain amount of platform credit, which is consumed by running Actors. The consumption rate is measured in Compute Units (CUs), where one CU equals one gigabyte-hour of RAM usage. This means a simple HTML scrape will cost far less than a complex job requiring extensive browser automation. While this model is harder to predict, Apify’s pricing can be more economical for certain types of jobs, especially with its pay-per-event option that charges for specific actions rather than just raw results.
Under 500k pages/month? Firecrawl is usually cheaper. Millions of lightweight pages or heavy anti‑bot workflows? A well‑optimized Apify scraper can win on total cost.
Cost-Effectiveness for Different Scales and Complexities
For smaller projects or predictable workloads (e.g., under 500,000 pages per month), Firecrawl is often the more cost-effective choice due to its simple pricing. However, Apify’s model provides advantages at scale. Its elastic infrastructure is ideal for massive, bursty jobs, such as crawling an entire e-commerce catalog overnight. A well-optimized Apify Actor that efficiently manages resources can be cheaper for scraping millions of simple pages or navigating sites with heavy anti-blocking technology. Performance-wise, Firecrawl’s pre-warmed browsers give it a latency advantage for real-time requests, while Apify’s ability to run thousands of Actors in parallel gives it a throughput advantage for large-scale bulk collection.
Integration Solutions and Recommended Use Cases
The true value of a data platform lies in how well it integrates into your existing workflows. Both Firecrawl and Apify offer robust integration options, but they are tailored to different kinds of applications.
Firecrawl excels in real-time AI applications with its seamless pipeline integration, whereas Apify is better suited for enterprise-level, multi-site data collection and complex automation.

Firecrawl’s Seamless Integration with AI Pipelines
Firecrawl is designed to be a plug-and-play solution for AI developers. It offers official SDKs for Python, JavaScript, and other languages, but its real strength lies in its native integrations with AI frameworks. With just a few lines of code, you can use its native LangChain and LlamaIndex loaders to fetch, clean, and chunk web content for RAG systems. These integrations handle tasks like pagination and metadata preservation automatically, allowing developers to focus on their AI logic rather than data plumbing. Firecrawl also connects easily with no-code platforms like Zapier and Make.com, making it accessible to non-developers.
Apify’s Enterprise-Grade CI/CD and Data Pipeline Support
Apify’s integrations reflect its enterprise focus. It is designed to be a managed data ingestion layer within larger engineering stacks. The platform offers a GitHub integration that allows teams to treat scraper code like any other microservice, complete with version control and CI/CD pipelines. For data engineering, Apify provides direct connectors that push results to cloud storage solutions like Amazon S3, Google Cloud Storage, and Azure Blob, or stream them to messaging systems like Kafka. This makes it an ideal solution for turning the platform into a managed data‑ingestion layer that feeds downstream analytics and business intelligence tools.
Choose Firecrawl when low‑latency access to web data and tight coupling with AI pipelines are top priorities. Its uniform API, natural‑language extraction, and sub‑second response times let you build chatbots, RAG systems, or research agents without wrestling with scraping logic.
Choosing a Platform: Real-time AI vs. Multi-site Bulk Collection
Your choice between Firecrawl and Apify should be guided by your primary workload.
If you are building AI applications that require low-latency, real-time access to clean web data, Firecrawl is likely the better fit. Its speed, simplicity, and tight AI integrations make it perfect for powering chatbots, research agents, and RAG systems.
If your needs are broader and more varied—requiring you to scrape dozens of different sites, support both technical and non-technical users, and meet enterprise compliance standards—then Apify delivers more value. Its vast marketplace of pre-built Actors and flexible, scalable infrastructure make it the superior choice for large-scale, multi-site data collection and complex automation workflows.
Conclusion
The choice between Firecrawl and Apify is a choice between focused, AI-native innovation and a comprehensive, mature ecosystem. Firecrawl offers a refreshingly simple and incredibly fast solution tailored specifically for the needs of modern AI applications. Apify provides a battle-tested, flexible platform with a vast library of tools capable of handling virtually any web data challenge at any scale.
Ultimately, the best platform depends entirely on your specific project requirements. Firecrawl is the clear winner for teams building real-time AI products that need clean data with minimal fuss. Apify excels in scenarios that demand breadth, enterprise-grade features, and the flexibility to tackle diverse and complex scraping tasks. Since both platforms offer generous free tiers, the best course of action is to test them with your own use cases. By doing so, you can confidently choose the right tool to turn the web’s endless information into valuable, actionable data.
Tools like this won’t fix everything, but they can make things easier.
Sometimes, getting unstuck is just about removing one small barrier.
If this sounds useful to you, Feel Free to Explore the Tool
Here →








